
In the realm of technological innovation, NVIDIA has once again broken new ground with its "Chat with RTX," a cutting-edge AI chatbot tool designed to run directly on PCs. This breakthrough is not just about bringing advanced AI capabilities to the desktop; it's about opening a gateway for businesses to develop their own offline, tailor-made Large Language Models (LLMs) without the constant need for cloud connectivity. Here's where DevWise steps in, ready to guide companies through the journey of harnessing this potent technology to meet their unique needs.
The Potential of Chat with RTX
Chat with RTX introduces the possibility of running a personal AI chatbot on your PC, leveraging NVIDIA's RTX 30 or 40 series GPUs. This application allows users to input YouTube videos and documents to generate summaries and find relevant answers based on the provided data, all processed locally. Despite its early development stage, the application demonstrates significant potential for data analysis, document search, and personalized AI interactions.
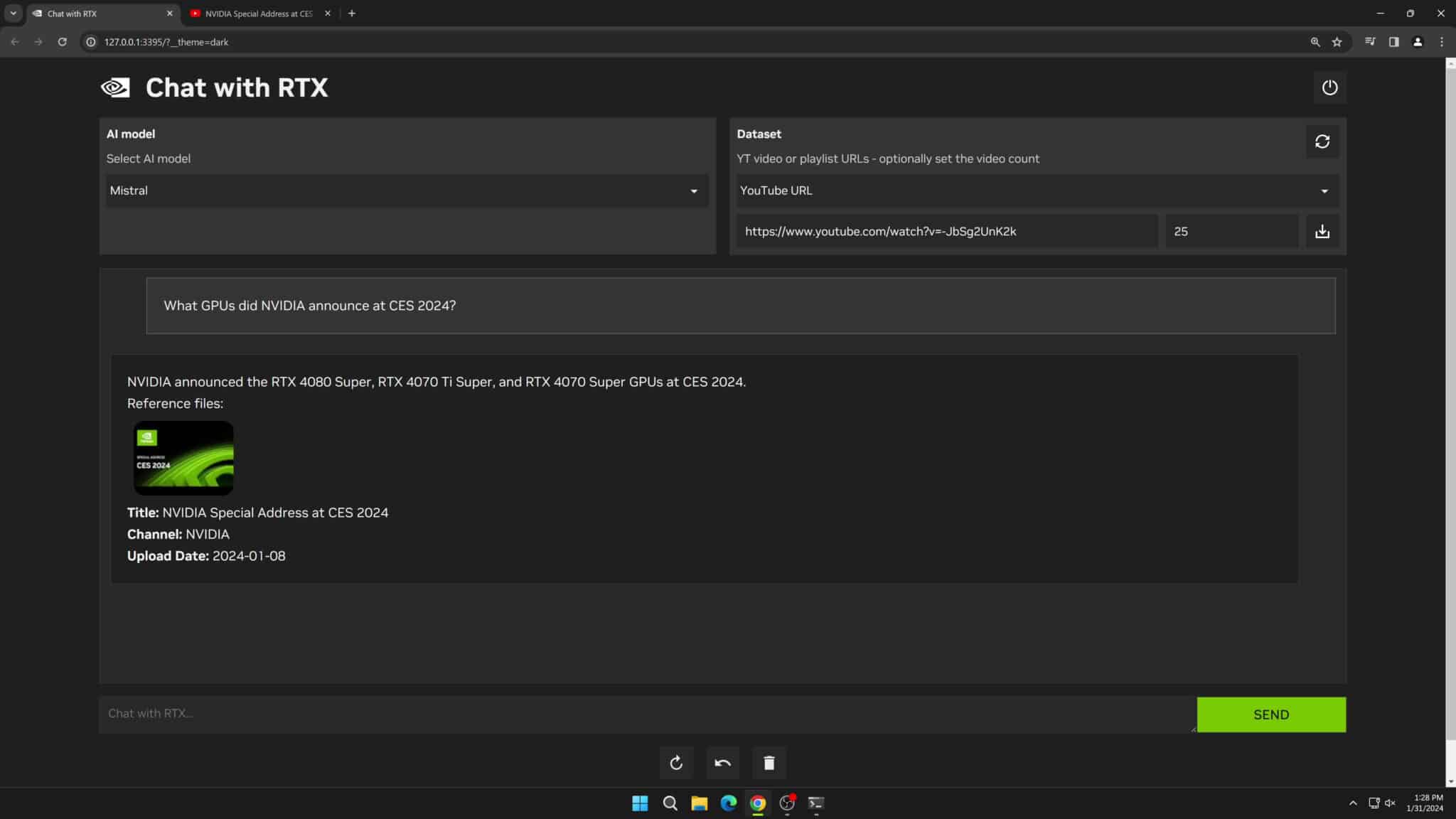
Why Offline LLMs Matter
In an era where data privacy and security are paramount, the ability to process and analyze data locally, without sending information to the cloud, is invaluable. Offline LLMs offer businesses the advantage of keeping sensitive information under wraps while ensuring real-time, efficient AI interactions. From reducing latency to customizing AI responses, offline LLMs empower businesses to leverage AI tailored to their specific operational needs and customer interactions.
Unlocking New Business Potentials
With NVIDIA's Chat with RTX, companies have the opportunity to redefine how they interact with AI technology. From enhancing customer service with personalized AI chatbots to streamlining operations through efficient data analysis, the potential use cases are vast and varied. By developing offline LLMs, businesses can unlock new levels of innovation, efficiency, and customer engagement, all while safeguarding their data.
NVIDIA's Chat with RTX vs LLaMA
In the context of AI development and deployment, Chat with RTX and LLaMA represent two distinct approaches within the AI landscape. Chat with RTX is NVIDIA's proprietary solution designed to leverage the company's advanced GPU technology for running AI-driven chat applications directly on a local PC, offering a streamlined and potentially more secure way to implement conversational AI without the need for cloud processing. This platform is particularly focused on enabling developers and researchers to utilize NVIDIA's hardware to maximize the efficiency and responsiveness of AI chatbots.
LLaMA, meanwhile, stands for a type of large language model that is designed to understand and generate human-like text, relying on vast datasets and sophisticated algorithms to process and produce language in a way that mimics human conversation. While not tied to a specific hardware platform like Chat with RTX, LLaMA's performance and capabilities are significantly enhanced when run on powerful computing hardware, such as NVIDIA's GPUs, which can accelerate the processing of the model's complex neural networks.
The critical distinction between Chat with RTX and LLaMA lies in their primary focus and utility: Chat with RTX is a tool that facilitates the deployment of AI models in a local environment, harnessing NVIDIA's GPU technology, whereas LLaMA is a model itself, focusing on the breadth and depth of language understanding and generation, which can be leveraged by various platforms, including Chat with RTX, for enhanced conversational AI applications.
How We make a difference
DevWise specializes in bridging the gap between cutting-edge AI technologies and business applications. Our expertise in software development, AI model training, and system integration positions us uniquely to assist companies in leveraging "Chat with RTX" for their LLM needs. Whether it's consulting on the optimal setup, developing bespoke software solutions, or navigating the complexities of AI training and integrations, DevWise is equipped to guide businesses through every step of their AI journey.
Conclusion
The future of business is undeniably intertwined with the advancement of AI technology. By embracing offline LLMs through NVIDIA's Chat with RTX, companies can stay ahead of the curve, ensuring they not only meet but exceed the evolving expectations of their customers and stakeholders. DevWise is here to make that transition seamless, offering the expertise and support businesses need to turn the potential of offline AI into a reality.
Questions? Comments? Feel free to contact us. We know how to help you to succeed on your next project.





